Data, the backbone of machine learning
You can compare machine learning without data to a car without fuel — you won’t get far if you don’t have any. So, whenever we start a new AI project, we first look at the data, as our systems are only as good as the data we use to train the model.
We often have to go through a data annotation process before we can get started with the data our customers provide us. Data annotation is the process of labeling data with relevant tags to help machines recognize what is needed and ultimately use it to make predictions. It can be done for text, images, audio, or video material, either by a human or automatically using tools. In this article, we will dive deeper into how we approach image annotation specifically for object detection, illustrated by one of our customer cases at pcfruit (read the entire case here).
Challenges of data annotation
There are two critical challenges to data annotation. First, let’s dive into the cost of annotating data. The price can vary as data annotation can be done manually or automatically. When doing it entirely manually, it requires a lot of time as it is labor intensive and therefore is quite expensive. Our customers often execute the data labeling task internally to reduce costs. Still, often, this results in substantial delays in the project, as this requires a lot of time and undivided attention.
The second challenge is accuracy; human errors can creep in when manually labeling an entire dataset. This directly impacts data quality and, in turn, the prediction of the machine learning models.
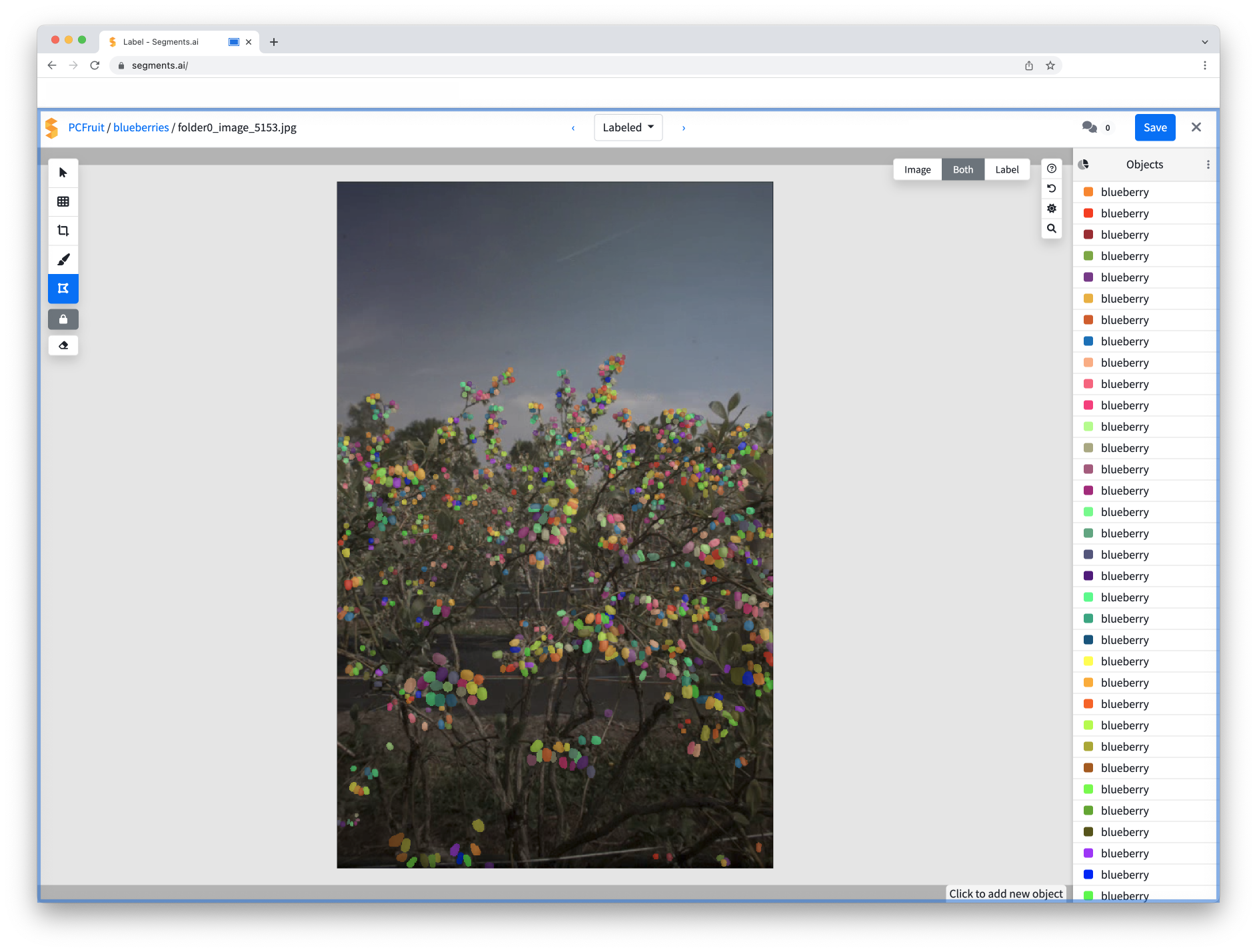 When applied to our customer case at pcfruit, we faced both challenges. To provide more context, for this particular case, we had to label a ton of blueberry blossoms in order to train an AI model to detect these blossoms later on. When we say a ton of flowers, we are talking about 196 pictures with an average of 736 blossoms per picture — a grand total of 144.297 flowers to be segmented. As you can see in the picture, the blossoms are not so easily segmented, so a lot of time and effort would go into manually labeling them. As this footage is quite overwhelming, the question of accuracy also arises. So, we looked for another solution: a data annotation tool. Because why wouldn’t we use an ML-driven solution to solve an ML-driven problem?
When applied to our customer case at pcfruit, we faced both challenges. To provide more context, for this particular case, we had to label a ton of blueberry blossoms in order to train an AI model to detect these blossoms later on. When we say a ton of flowers, we are talking about 196 pictures with an average of 736 blossoms per picture — a grand total of 144.297 flowers to be segmented. As you can see in the picture, the blossoms are not so easily segmented, so a lot of time and effort would go into manually labeling them. As this footage is quite overwhelming, the question of accuracy also arises. So, we looked for another solution: a data annotation tool. Because why wouldn’t we use an ML-driven solution to solve an ML-driven problem?
Using a data annotation tool
Machine learning-assisted annotation
As AI-solution builders, we couldn’t pass on the opportunity to have an ML-driven solution help us, so we dove into the wonderful world of ML-assisted annotation and chose Segments.ai, a specialized software, as our annotation tool.
The first thing that drew us to the platform was its user interface. Segments.ai offers a convenient user interface, already speeding up labeling drastically. Second, they provide intelligent labeling tools such as their Superpixel and Autosegment technology to mark objects and regions with unseen speed and accuracy. Third, by training your AI model with the already labeled data, you can upload your model predictions into Segments.ai and turn these predictions into perfectly labeled data. Last but not least, the platform is very engineering friendly with a best-practice API and SDK to push in and pull out data.
In the pcfruit case, the autosegment technology already sped up the process immensely. Already a good percentage of the blossoms were detected, so less manual work was required. In addition, when we want to move beyond our proof of concept, we can easily upload our model predictions into the tool to label new data even faster.

Humans in the loop
Data quality drastically improves when you combine the power of machine learning-assisted annotation with a human-in-the-loop approach. Integrating human judgment in the data labeling process reduces bias and improves data quality while still benefiting from an accelerated cycle time. Segments.ai offers a dedicated external annotation workforce to maximize annotation quality.
So, back to our customer case at pcfruit. In the end, labeling all images and segmenting every blossom pixel took approximately ten workdays. Imagine three scenarios: one where the client appointed one of their employees to mark the data, one where we had chosen one of our AI engineers to go through the data, or one where we outsourced the annotation task to Segments.ai’s dedicated workforce. You can probably already guess why we went for the third option. Let’s go over some of our reasons.
First, our client’s employees have probably never labeled data before; our AI engineer is trained to work on AI models; and Segments.ai’s annotators specialize in annotating in the platform. The annotators are trained and as a result, much faster in working with the platform. Second, hiring an external workforce is only a fraction of the cost of an AI engineer or an internal employee. Ultimately, we labeled all our data in 50% of the turnaround time for only one-tenth of the price. Of course, if we would have onboarded a larger labeling team, we would have received the labeled data even quicker.
Best annotation practices
Need to start labeling your datasets? Think of these best practices before getting started so you can feed your data-hungry models what they need to perform well:
- Collect enough quality data: If your annotation task seems time-consuming, you are probably doing something wrong. Ensure that you have enough quality data to feed your models. Otherwise, your quality will suffer, and you will have to get started again eventually.
- Annotation guidelines: Develop data annotation guidelines to ensure everything is labeled the same way. This results in more data consistency and accuracy.
- Use dedicated software: Using machine learning solutions to identify most of your items already to be labeled can drastically speed up your lead time.
- Label a subset yourself: Before deciding to outsource labeling, get the AI engineering team to label some data themselves. This way, they can understand accuracy needs and edge cases better.
- Leverage an external workforce: Opt for a quicker lead time and outsource the time-consuming data labeling aspect.
- Human-in-the-loop approach: Use a combination of data annotation software and a human-in-the-loop approach. This way, the annotators can focus on edge cases and reduce bias in the dataset.
Keep these in mind, and if you don’t know where to get started, reach out to us!