Why not use some really serious, cool, advanced AI technologies to make something very fun and silly? Well, that is exactly what we aim to do on our so-called Brainjar days. During a Brainjar day, everyone on the team receives the opportunity to experiment with something of their choice. So, I thought: what if I could use AI image generation to merge two faces?
Oh, and I'm not just talking about a face swap. I'm talking about actually generating a completely new face made of features of two original faces. And even better: what if I could find a way to visualize the morphing process from one face to the other? Let's see how far I got with my Frankenstein-ish experiment!

Facemorphing
Two months ago, everyone at Raccoons got a new company portrait picture. Since AI sits deep in our roots, we thought it would be a fantastic idea to generate merged 'Frankenstein' faces of all of us and show the morphing process between them all. The result is kind of freaky and most interesting to look at. Here is a small snippet of what we're trying to achieve:
Using StyleGAN 2
For the morphing part of this experiment, we use StyleGAN2. In AI terms, you can describe StyleGAN as a generative adversarial network that can generate high-quality and large-resolution synthetic images. So, StyleGAN2, as its name implies, is the next major iteration after the original StyleGAN. It adds a few core improvements and will be the backbone technology we use today.
Nvidia researchers originally designed StyleGAN2 to generate highly realistic-looking faces. For example, take a look at ThisPersonDoesNotExist. This site is full of faces of people who don’t really exist. They used StyleGAN to generate AI faces that look photorealistic. This can be particularly useful in the world of stock photography as there is no need to worry about the consent or privacy of the model.
So, clearly, we can see that StyleGAN2 can generate some convincing stuff. But there is a problem. You see, StyleGAN2 was not designed to take input. Instead, it generates a random face using a random input seed every time. In this case, we don't want StyleGAN to generate random faces. We want to generate our faces and then merge those faces for a morphing effect.
Autoencoders to the rescue!
Autoencoders are used in a vast range of AI solutions and come in handy to solve our use case. Let's briefly examine what an autoencoder is and how it will help us solve our problem.
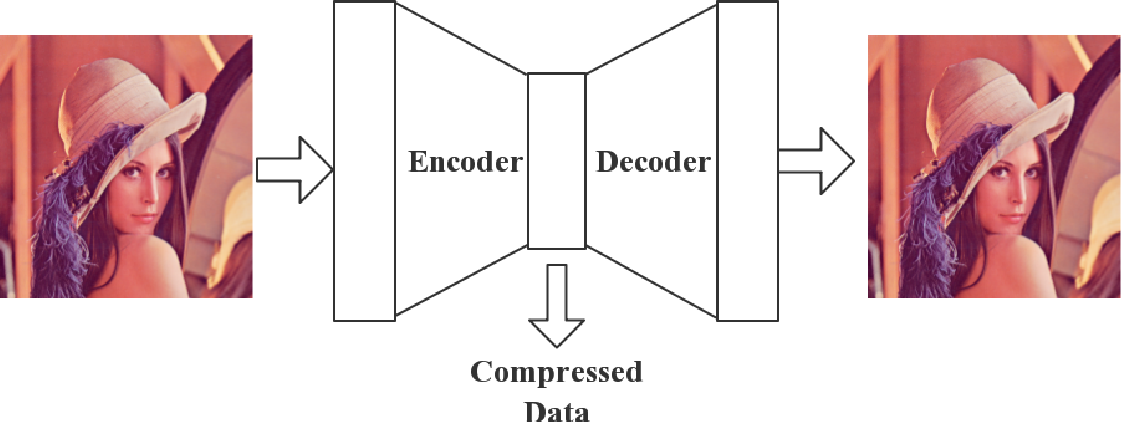
As you can see in the simplified image above, an autoencoder is an AI architecture that consists of two neural networks: an encoder and a decoder. An encoder is a neural network that will compress the input layer into a condensed output layer. The compressed data that comes out of this network is known as the 'latent space'. What precisely the latent space contains is impossible to visualize. It is a black box with limited neurons that the network will automatically learn to use as efficiently as possible to store as much of the original input into the limited latent space.
As you may have guessed, the decoder is a neural network trained to do the exact opposite of the encoder. It will take the latent space data as an input and create a full-size output that matches the original encoder input as closely as possible.
At first glance, an AI system trained to match its input with its output might seem useless. The magic, however, happens in the latent space. Let me give you an example. Online video streaming services often use autoencoder networks, as they use an encoder on the server side to send the video, have the network carry only the data of the latent space (which is way smaller than the entire file), and have a decoder on the client side to display the final video. If the network is trained well, there will be a minimal quality loss but massive data and cost savings, especially when you combine the autoencoder with traditional compression techniques.
Back to our challenge: how can we use these autoencoders in combination with StyleGAN to generate our faces?
StyleGAN + Autoencoders
We can train StyleGAN to function as the generator in our autoencoder. We then use a ResNet encoder to transform our faces into the complex latent space of StyleGAN. This latent space is 512-Dimensional (!).
Below, you can see the result.

Let's appreciate what's happening here. ResNet takes the ground truth image and converts it into a 512-dimensional latent space. This is a black box containing 512 values that are used to generate any possible face. StyleGAN then used that limited information to generate a close approximation of the original face. The results are pretty good. Not perfect, sure, but comparing the ground truth and the generated face side-by-side isn't what we'll do in the final video. If you know Maarten and only get presented with the generated image, it can be very convincing.
Morphing
This is where things get exciting, even though most of the hard work is already done. We need to morph from one face to the other, which is fairly simple with our current setup. First, let's generate the latent space of our two faces.
Now, a video is typically 24 frames per second. If we want the morphing to take, say, 1.5 seconds, this means we need 36 frames. So, all we need to do now is to transform all the values in the first latent space into all the values of the second latent space. We will do this in 36 steps; this way, we have a slight change in every frame. Then for each frame, we take the current state of the latent space and use StyleGAN to generate the face of that frame. To include multiple people, you could repeat this process as often as you like. Our final video contains 50 faces!
The result
StyleGAN 3
So far, our methodology results in a pretty cool video, but it's not perfect. If you look closely, you can see that when textures move around during the morphing, their position seems static in the frame, but the movement gets shown by moving a mask of the texture. This artifact is called aliasing. Nvidia has worked on a new version of StyleGAN specifically to fix this issue. Meet StyleGAN 3. This latest version of StyleGAN results in a realistic motion of the faces in the video. You can see a noticeable difference in the example below:
You can read more about StyleGAN 3 and how it works here. StyleGAN3 is still relatively new, so we haven't used it yet in this video, but we are definitely interested in taking a closer look in the future. Stay tuned!