The impact of machine learning on the environment. Do you often reflect and think about it? Where does the responsibility of making green choices lie? Users, researchers, programmers, hardware developers, or somewhere else?
Regardless of who is responsible, I would say that the first step to ecological machine learning systems is being aware and, in turn, bringing awareness to others. Sustainability is a hot topic and even a need, especially since our technology-consuming society wants to keep growing. I believe that being well-informed leads to better choices or at least leaves us thinking about them. In this blog, I aim to provide an objective, academically-based overview of sustainable decisions regarding machine learning.
There are a couple of good scientific articles on the topic, and it is essential to understand and interpret them correctly. I would personally stay away from magazine articles or quick reads that don't cite scientific papers. Very often, these quick reads lead to the wrong comparison of values. Moreover, they don't show the proportion of comparison of numbers or expose only one side of the story.

Carbon impact
Over the years, machine learning models have become increasingly powerful in their abilities. Advances in techniques and hardware for training deep neural networks have recently enabled impressive accuracy improvements across many fundamental NLP and computer vision tasks. As a result, training a state-of-the-art model now requires substantial computational resources that demand considerable energy and associated financial and environmental costs.
Sustainable machine learning has led to some experts developing tools capable of monitoring the carbon impact behind machine learning models, as well as laying down the groundwork for mitigation approaches like carbon-aware computing. Most of the tools measuring AI's carbon footprint are a work in progress, and as some recent studies show, their mileage can vary depending on the context.
Developing greener AI systems is not influenced by solely one factor, resulting in quite dispersed solutions. There are diverse areas of action, however. This article will focus mainly on three points of view: machine learning programmers, hardware developers and researchers, and finally, Cloud Servers.
1. Machine learning programmers
A small practice goes a long way…
Data best practices
- Correct data preprocessing — Ensure your data is ready to be fed to a model in a valid, cleaned format with the needed information. It is a big waste of resources to be halfway through the training process and then realize you missed an essential aspect of the preprocessing of your data. This goes hand to hand with the next point; data usefulness.
- Data usefulness — Humans don't pay attention to every last detail - why should our models? Let's say we have a 15-minute video from a camera that rides through a field of berries on a production farm. It would not be efficient to train or run inference on the frames that do not contain the field section with bushes, especially berries. This might seem quite obvious for this example, but in some cases might go entirely forgotten with costs to model accuracy and higher needs for computational costs, and a higher carbon footprint.
MLOps best practices
- Beautiful code — Simply said, document well. Nobody wastes time or resources: typing hints, doc strings, and good variable names.
- Try your model architecture in a small set of data — In case something doesn't work in your pipeline, you didn't spend computer resources in vain. Also, this helps to get a better 'grip' on processes that can be improved in your ML life cycle.
- Don't lose your progress and track it — Working in an organized way can help in many aspects. For example, create model checkpoints.
DYOR - Do your own research
- Read — Understand your problem and read about what has already been experimented on and tested before going into action.
- Use pre-trained models — Think about transfer learning. This translates into less need for training time. Also, better model performance typically can be achieved in case of fewer data.
- Model architecture choice — Some model architectures are more eco-friendly than others. You never know if a 'greener model' can solve your problem, so think about it once in a while.
Cloud vs. on-premise debate
- Mechanization — Computing in the cloud rather than on-premise reduces energy usage and, therefore, emissions by 1.4x–2x. Cloud-based data centers are new, custom-designed warehouses equipped for energy efficiency for 50,000 servers, resulting in outstanding power usage effectiveness (PUE). On-premise data centers are often older and smaller and thus cannot amortize the cost of new energy-efficient cooling and power distribution systems.
- Deployment type — Cloud or edge (as network transfer, hardware optimization on edge, and specialized hardware edge devices might come into play).
- Rely on cloud services — The prohibitive start-up cost of building in-house resources forces resource-poor groups to rely on cloud computing services such as AWS, Google Cloud, and Microsoft Azure. These services provide valuable, flexible, and often environmentally friendly computing resources. However, it is more cost-effective for academic researchers, who often work for non-profit educational institutions and whose research is funded by government entities, to pool resources to build shared computing centers at funding agencies, such as the U.S. National Science Foundation.
- Map optimization — Some clouds let customers pick the location with the cleanest energy, reducing the gross carbon footprint by 5x–10x. While one might worry that map optimization could lead to the greenest spots quickly reaching maximum capacity, user demand for efficient data centers will result in continued advancement in green data center design and deployment. For example, Microsoft is now making information on the electricity consumption of its hardware available to researchers who use its Azure service.
💡 Tip: experiment with Code Carbon
This package enables developers to track emissions, measured as kilograms of CO₂-equivalents, or CO₂eq, to estimate their work's carbon footprint. To do this, they useCO₂-equivalents [CO₂eq], a standardized measure used to express the global warming potential of various greenhouse gasses, the amount of CO₂ that would have the equivalent global warming impact.
For computing, which emits CO₂ via the electricity it consumes, which is generated as part of the broader electrical grid – for example, electricity generated by combusting fossil fuels such as coal – carbon emissions are measured in kilograms of CO₂-equivalent per kilowatt-hour.
It's super easy to use! You can go for the online mode or offline mode. For example, with the offline mode on a very high level, you have to:
→ pip install codecarbon;
→ Create an object to track your training - OfflineEmissionsTracker; → Get an emissions CSV file.
Webpage: https://codecarbon.io/#howitwork
Documentation: https://mlco2.github.io/codecarbon/
2. Hardware developers and researchers
Efficient machines, algorithms, and measuring…
-
Appropriate hardware
Using processors and systems optimized for ML training versus general-purpose processors can improve performance and energy efficiency by 2x–5x. To illustrate this, here's a great example:
Vivienne Sze, an MIT professor, has written a book on efficient deep nets. In collaboration with book co-author Joel Emer, an MIT professor, and researcher at NVIDIA, Sze has designed a flexible chip to process the widely-varying shapes of both large and small deep learning models. Called Eyeriss 2, the chip uses ten times less energy than a mobile GPU.
Its versatility lies in its on-chip network, called a hierarchical mesh, which adaptively reuses data and adjusts to the bandwidth requirements of different deep learning models. After reading from memory, it reuses the data across as many processing elements as possible to minimize data transportation costs and maintain high throughput.
"The goal is to translate small and sparse networks into energy savings and fast inference," says Sze. "But the hardware should be flexible enough to also efficiently support large and dense deep neural networks."
-
Need to quantify - Developing good measuring tools
The main problem to tackle in reducing AI's climate impact is quantifying its energy consumption and carbon emission and making this information transparent. Crawford and Joler wrote in their essay that the material details of the costs of large-scale AI systems are vague in the social imagination, to the extent that a layperson might think that building a machine learning-based system is a simple task. Part of the enigma lies in the absence of a standard of measurement.
An interdisciplinary team from the Allen Institute for AI, Microsoft, Hebrew University, Carnegie Mellon University, and AI start-up Hugging Face is presenting a more sophisticated approach that uses location-based and time-specific data to measure more accurately the operational carbon emissions of popular AI models.
-
Developing more energy-efficient algorithms
-
Publish your green or not-so-green findings honestly
3. Cloud services
Location and time matter…
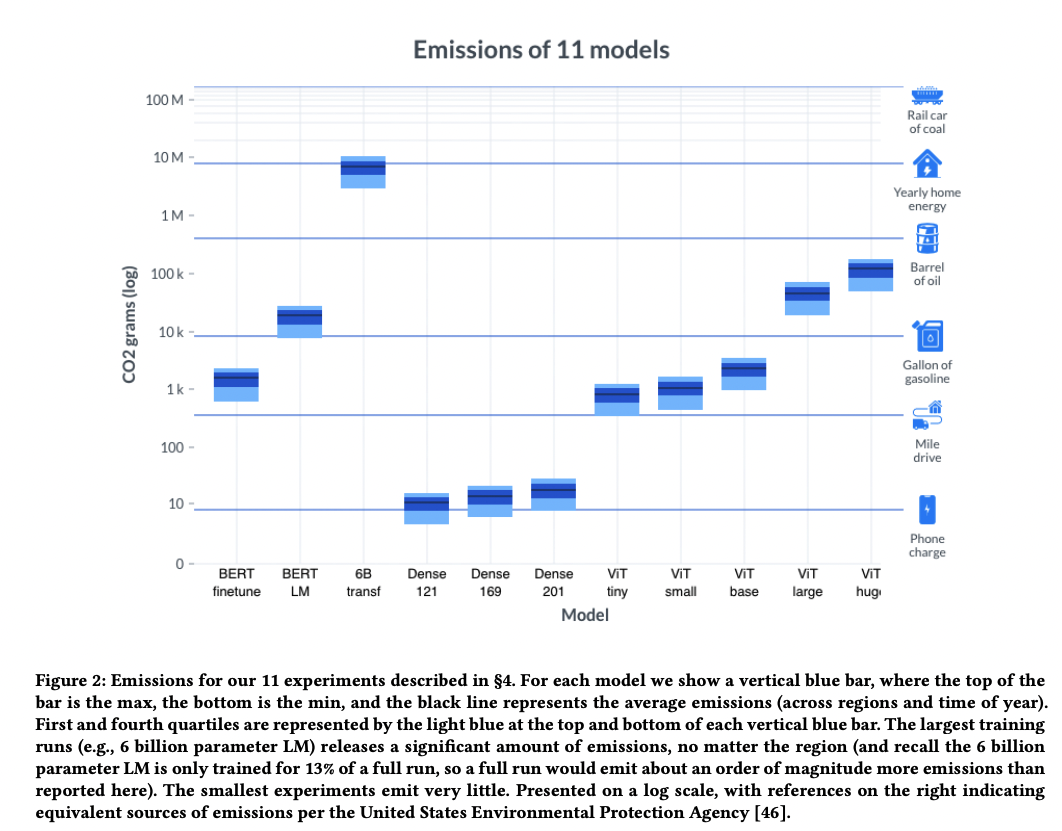
The carbon footprints range from facilities in different locations because of variations in power sources and fluctuations in demand. The results in the graphic below demonstrate the variations in carbon emission for training a BERT model.
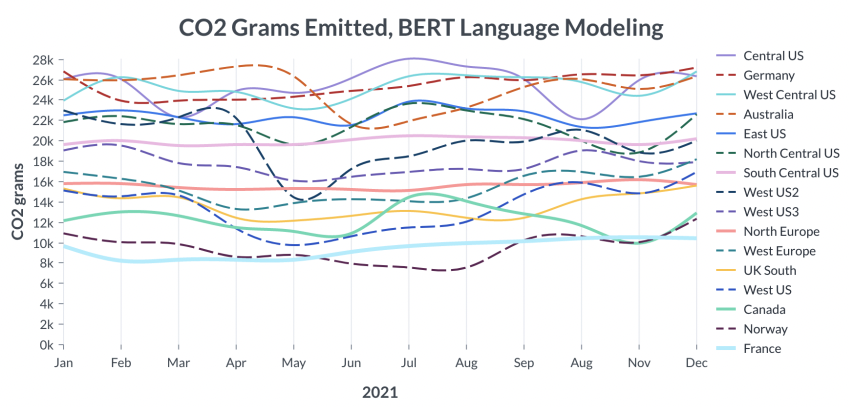
It can be observed that data centers in the central United States or Germany emitted 22–28 kilograms of carbon dioxide, depending on the time of year. This was more than double the emissions generated by doing the same experiment in Norway, which gets most of its electricity from hydroelectric power, or France, which relies mainly on nuclear power.
Moreover, the time of day at which experiments run matters. For example, training in Washington during the night, when the state's electricity comes from hydroelectric power alone, led to lower emissions than doing so during the day, when power also comes from gas-fired stations.
A great deal of the responsibility for emissions lies with the cloud provider rather than the researcher, since the energy source of the cloud provider has the bigger impact on this matter. For this reason, the providers could adopt flexible strategies that allow machine-learning runs to start and stop at times that reduce emissions. On this matter, I advise anyone to read this publication.
Conclusion
With so many proposed solutions, where should you start? I would go for the 'close-to-us' decisions, where the action is possible. Once in a while, a chat with others can have the so-called 'butterfly effect'…
To cut it green:
- Good coding practices regarding readability and efficiency. Adding to this good choice of models, quality data, and experimenting with measuring frameworks.
- Developing the right hardware for ML, monitoring tools, proper storage, and publishing the associated consumptions;
- Better energy choices from cloud companies - optimizing the energy sources' location and time, as this has been proven to be the most contributing factor of all of the mentioned!
Good reads
For the ones with a green appetite:
- https://aws.amazon.com/aws-cost-management/aws-customer-carbon-footprint-tool/ - customer carbon footprint tool
- https://codecarbon.io/#howitwork - framework for tracking of carbon emissions
- https://facctconference.org/static/pdfs_2022/facct22-145.pdf?utm_source=thenewstack&utm_medium=website&utm_campaign=platform - scientifical paper
- https://arxiv.org/pdf/1906.02243.pdf - scientifical paper
- https://www.rle.mit.edu/eems/research/ - hardware development